第四节 分支节点页
分支节点主要用来构建索引,方便提升查询效率。下面我们来看看boltdb的分支节点的数据是如何存储的。
1. 分支节点页中元素定义:
分支节点在存储时,一个分支节点页上会存储多个分支页元素即branchPageElement。这个信息可以记做为分支页元素元信息。元信息中定义了具体该元素的页id(pgid)、该元素所指向的页中存储的最小key的值大小、最小key的值存储的位置距离当前的元信息的偏移量pos。下面是branchPageElement的详细定义:
// branchPageElement represents a node on a branch page.
type branchPageElement struct {
pos uint32 //该元信息和真实key之间的偏移量
ksize uint32
pgid pgid
}
// key returns a byte slice of the node key.
func (n *branchPageElement) key() []byte {
buf := (*[maxAllocSize]byte)(unsafe.Pointer(n))
// pos~ksize
return (*[maxAllocSize]byte)(unsafe.Pointer(&buf[n.pos]))[:n.ksize]
}
2. 分支节点页page中获取下标为index的某一个element的信息和获取全部的elements信息
// branchPageElement retrieves the branch node by index
func (p *page) branchPageElement(index uint16) *branchPageElement {
return &((*[0x7FFFFFF]branchPageElement)(unsafe.Pointer(&p.ptr)))[index]
}
// branchPageElements retrieves a list of branch nodes.
func (p *page) branchPageElements() []branchPageElement {
if p.count == 0 {
return nil
}
return ((*[0x7FFFFFF]branchPageElement)(unsafe.Pointer(&p.ptr)))[:]
}
下图展现的是非叶子节点存储方式。
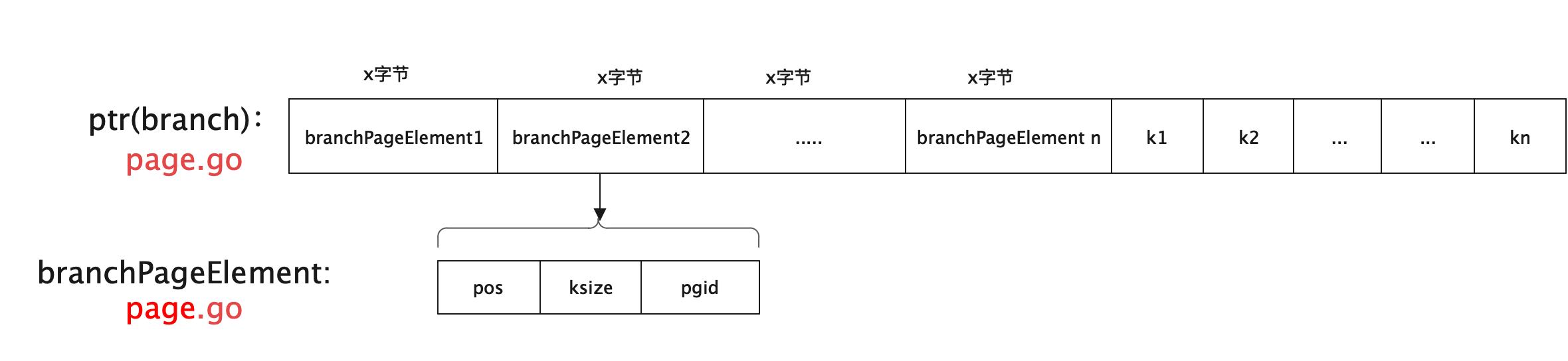
在内存中,分支节点页和叶子节点页都是通过node来表示,只不过的区别是通过其node中的isLeaf这个字段来区分。下面和大家分析分支节点页page和内存中的node的转换关系。
下面在介绍具体的转换关系前,我们介绍一下内存中的分支节点和叶子节点是如何描述的。
// node represents an in-memory, deserialized page.
type node struct {
bucket *Bucket
isLeaf bool
unbalanced bool
spilled bool
key []byte
pgid pgid
parent *node
children nodes
inodes inodes
}
在内存中,具体的一个分支节点或者叶子节点都被抽象为一个node对象,其中是分支节点还是叶子节点主要通通过其isLeaf字段来区分。下面对分支节点和叶子节点做两点说明:
对叶子节点而言,其没有children这个信息。同时也没有key信息。isLeaf字段为true,其上存储的key、value都保存在inodes中
对于分支节点而言,其具有key信息,同时children也不一定为空。isLeaf字段为false,同时该节点上的数据保存在inode中。
为了方便大家理解,node和page的转换,下面大概介绍下inode和nodes结构。我们在下一章会详细介绍node。
const (
bucketLeafFlag = 0x01
)
type nodes []*node
func (s nodes) Len() int { return len(s) }
func (s nodes) Swap(i, j int) { s[i], s[j] = s[j], s[i] }
func (s nodes) Less(i, j int) bool { return bytes.Compare(s[i].inodes[0].key, s[j].inodes[0].key) == -1 }
// inode represents an internal node inside of a node.
// It can be used to point to elements in a page or point
// to an element which hasn't been added to a page yet.
type inode struct {
// 表示是否是子桶叶子节点还是普通叶子节点。如果flags值为1表示子桶叶子节点,否则为普通叶子节点
flags uint32
// 当inode为分支元素时,pgid才有值,为叶子元素时,则没值
pgid pgid
key []byte
// 当inode为分支元素时,value为空,为叶子元素时,才有值
value []byte
}
type inodes []inode
3. page->node
通过分支节点页来构建node节点
// 根据page来初始化node
// read initializes the node from a page.
func (n *node) read(p *page) {
n.pgid = p.id
n.isLeaf = ((p.flags & leafPageFlag) != 0)
n.inodes = make(inodes, int(p.count))
for i := 0; i < int(p.count); i++ {
inode := &n.inodes[i]
if n.isLeaf {
// 获取第i个叶子节点
elem := p.leafPageElement(uint16(i))
inode.flags = elem.flags
inode.key = elem.key()
inode.value = elem.value()
} else {
// 树枝节点
elem := p.branchPageElement(uint16(i))
inode.pgid = elem.pgid
inode.key = elem.key()
}
_assert(len(inode.key) > 0, "read: zero-length inode key")
}
// Save first key so we can find the node in the parent when we spill.
if len(n.inodes) > 0 {
// 保存第1个元素的值
n.key = n.inodes[0].key
_assert(len(n.key) > 0, "read: zero-length node key")
} else {
n.key = nil
}
}
4. node->page
将node中的数据写入到page中
// write writes the items onto one or more pages.
// 将node转为page
func (n *node) write(p *page) {
// Initialize page.
// 判断是否是叶子节点还是非叶子节点
if n.isLeaf {
p.flags |= leafPageFlag
} else {
p.flags |= branchPageFlag
}
// 这儿叶子节点不可能溢出,因为溢出时,会分裂
if len(n.inodes) >= 0xFFFF {
panic(fmt.Sprintf("inode overflow: %d (pgid=%d)", len(n.inodes), p.id))
}
p.count = uint16(len(n.inodes))
// Stop here if there are no items to write.
if p.count == 0 {
return
}
// Loop over each item and write it to the page.
// b指向的指针为提逃过所有item头部的位置
b := (*[maxAllocSize]byte)(unsafe.Pointer(&p.ptr))[n.pageElementSize()*len(n.inodes):]
for i, item := range n.inodes {
_assert(len(item.key) > 0, "write: zero-length inode key")
// Write the page element.
// 写入叶子节点数据
if n.isLeaf {
elem := p.leafPageElement(uint16(i))
elem.pos = uint32(uintptr(unsafe.Pointer(&b[0])) - uintptr(unsafe.Pointer(elem)))
elem.flags = item.flags
elem.ksize = uint32(len(item.key))
elem.vsize = uint32(len(item.value))
} else {
// 写入分支节点数据
elem := p.branchPageElement(uint16(i))
elem.pos = uint32(uintptr(unsafe.Pointer(&b[0])) - uintptr(unsafe.Pointer(elem)))
elem.ksize = uint32(len(item.key))
elem.pgid = item.pgid
_assert(elem.pgid != p.id, "write: circular dependency occurred")
}
// If the length of key+value is larger than the max allocation size
// then we need to reallocate the byte array pointer.
//
// See: https://github.com/boltdb/bolt/pull/335
klen, vlen := len(item.key), len(item.value)
if len(b) < klen+vlen {
b = (*[maxAllocSize]byte)(unsafe.Pointer(&b[0]))[:]
}
// Write data for the element to the end of the page.
copy(b[0:], item.key)
b = b[klen:]
copy(b[0:], item.value)
b = b[vlen:]
}
// DEBUG ONLY: n.dump()
}